Visualizing WhatsApp Chat History
written on 06/08/2015
It's been quite some time since i wrote these scripts to visualize and analyze whatsapp chat histories. Now, considering the fact that i'm relatively free, looking for jobs and stuff i finally decided to write a new blog post(sure, nobody cares, but..but.. if someone likes this they could use this and further expand on it. YOLO and all that.). Clarifying first and for all, my laptop backups and memorycards are full of WhatsApp histories, but they are all encrypted ".bak" files and considering that i was a "Blackberry Boy" - (the BIS internet plan), that made it impossible to send the .txt files to myself for analysis. Bummer. Bummer. Bummer.
Anyways, i just started asking my friends to send me the Chat history between us. Now, it was necessary to get chat histories from dudes who i've been talking to since the past 2-3 years(Needed Temporal Data, the more data points the better.). So, the problem with asking other people for WhatsApp chat history is that the text output is not standardized. Android guys have different format, Apple punks their own et cetra et cetra. Hence, i could not work with a single python script for all distinct types of data input. Anyways, i'll just explain 1 of the scripts i used, the one i used for the Apple Chat history.
Word of Advice: It is better to install SublimeText text editor. Seriously. It is amazing, with it's regex and library tools and also the multi-line cursor possibilitites. Sure, Python regex can parse almost everything easily, but you still have to think about all the possible breaking points like line breaks and identation. One can't think about all the errors that might creep up in the input data. So it is much better to just open the ".txt" data inputs in SublimeText and then glancing at it and manually handle all the data errors that are there. Just saying. BASH/Python/Perl Script Ninjas can just ignore the advice and run there regex's..
Problem Statement.
The idea is to visualize the Temporal Data ie. some data value plotted over a period of time. So, the data is collected through saving the Whatsapp Chat logs taken over a period of 1 Month to 2 Years. It has all the dates taken and then plotted as Message Count between the user ie. ”Me” and ”Friends”.The Data
The data is in the form of messages between people attached with the appropriate time and date stamps. The data is spread across different communication days.05/12/12 10:50:12 AM: AV: Bhai, delhi has pollution. 05/12/12 5:35:49 PM: ABC: Pollution ko maar goli. Thandi hai 05/12/12 5:41:12 PM: AV: Lol... Vo to hain hee... Raat ko jaada. 05/12/12 5:41:50 PM: AV: my parents they bought me the new one I wanted, Masst blackberry hain.
(AV = Ankit Vadehra(ie. Me)); && ABC = (A Friend);. We require the dates ie. 15/03/13. Hence we distribute the dates in two files, one for each user. Then we can calculate the number of messages sent by each person and visualize them in the temporal form. We also take the messages sent and then construct the word clouds so that we can see the most frequently used words. That's about it. The gist of what i'm trying to do. No Hi-Fi nonsense. YOLO-Again!!
Mumbo-Jumbo, Coding..
The idea is to divide the project in 2 halfs. Seperate the Chat-History into Dates and the Message(Since i'm trying to distribute the data in the form of distinct dates, i'm ignoring the timestamp attached with each message. Consider only the date.). The Dates will help in visualizing the frequency of messages over a period of time and the messages are feeded into the online word-cloud generator to see the most frequent words used.(The word cloud can also be generated using Python, but the online generators like wordly etc are much more prettier. Ha Ha Ha Ha ;) ).dates.py me = "Ankit Vadehra:" you = "ABC:" ankit_date = open("ankit_date.txt","w") ABC_date = open("ABC_date.txt","w") x = open("ABC.txt","r") y = x.readline().decode('utf-8-sig').encode('utf-8') while y: if (me in y): temp = y.split(" ",1) ankit_date.write(temp[0]+"\n") elif (you in y): temp = y.split(" ",1) ABC_date.write(temp[0]+"\n") y = x.readline().decode('utf-8-sig').encode('utf-8')
Here, ABC= My friends name obscured for privacy and all that stuff, you know. The variables
me && you are user specific. They need to contain the name in the chat history, however way you get it in the ".txt" file. Now we gotta parse the chat history, line by line and seperate the dates in different ".txt" files that will be used later for counting the number of messages per day and later for visualization. Now, i'm gonna quickly explain the Python split function here.Let's say that the variable
y contains each line in the chat file per iteration. So,y = 13/10/13 10:20:28 pm: ABC: Python is niceNow,
temp = y.split(" ",1) creates an array of temp. It splits the data element in 2 parts, seperated by the first " " blank space. Hence, we get:temp[0] = 13/10/13
temp[1] = 10:20:28 pm: ABC: Python is niceThe
if condition just states whether the name in the line is me-or-you, and then writes the dates, ie. temp[0] in seperate ".txt" files for the 2 users. After running this we get 2 outputs: ankit_date.txt && ABC_date.txt and the output looks somewhat like this:02/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 13/10/13 ...
Now, the second part is seperating the messages and also cleaning them, removing all emoticons and unecessary punctuations, so that all remains is the proper words in the message.
import re b = open("ABC.txt","r") a = open("messages.txt","w") y = b.readline().decode('utf-8-sig').encode('utf-8') while y: if(y != '\r\n'): temp = y.split(": ",2) x = temp[2] x = re.sub('([\:\;][\)\|\\\/dDOoPp\(\'\"][\(\)DOo]?)','',x) x = re.sub('[?\.#_]','',x) x = re.sub('[\s]+',' ',x) a.write(x+"\n") y = b.readline()
temp = y.split(": ",2) does is breaks temp into an array of the form:y = 13/10/13 10:20:28 pm: ABC: Python is nice temp[0] = 13/10/13 10:20:28 pm: ABC: temp[1] = Python is nice
x = re.sub('([\:\;][\)\|\\\/dDOoPp\(\'\"][\(\)DOo]?)','',x) x = re.sub('[?\.#_]','',x) x = re.sub('[\s]+',' ',x)
Can Python be used to design and implement Frontend design of websites, or only backend/server support I know PHP does both, backend+frontend Web2py and django frontend design kar sakte hain kya I guess Django is a framework and lets u do that
Now, we have to calculate the number of times a date has occured. For that we will use the Python "Counter" function.
x = open("dates.txt",'r') y = x.read() from collections import Counter print Counter(y.split('\n'))
29/04/2015 120 23/04/2015 34 15/04/2015 25 29/03/2015 15 27/04/2015 12 25/04/2015 11 22/04/2015 6 30/04/2015 3 30/03/2015 1
Visualizing the Temporal Data.
We use the Python-Matplotlib library for simple temporal printing of the message count WRT the dates.import numpy as np import matplotlib.pyplot as plt import matplotlib.dates as mdates days, messages = np.loadtxt("ankit_count.csv", unpack=True, converters={ 0: mdates.strpdate2num('%d/%m/%Y')}) days2, messages2 = np.loadtxt("ABC_count.csv", unpack=True, converters={ 0: mdates.strpdate2num('%d/%m/%Y')}) plt.xlabel('Date') plt.ylabel('Message Count') plt.plot_date(x=days, y=messages,color='m',label='Me',linestyle=':') plt.plot_date(x=days2, y=messages2,color='c',label='Friend',linestyle='-.') plt.legend() plt.show()
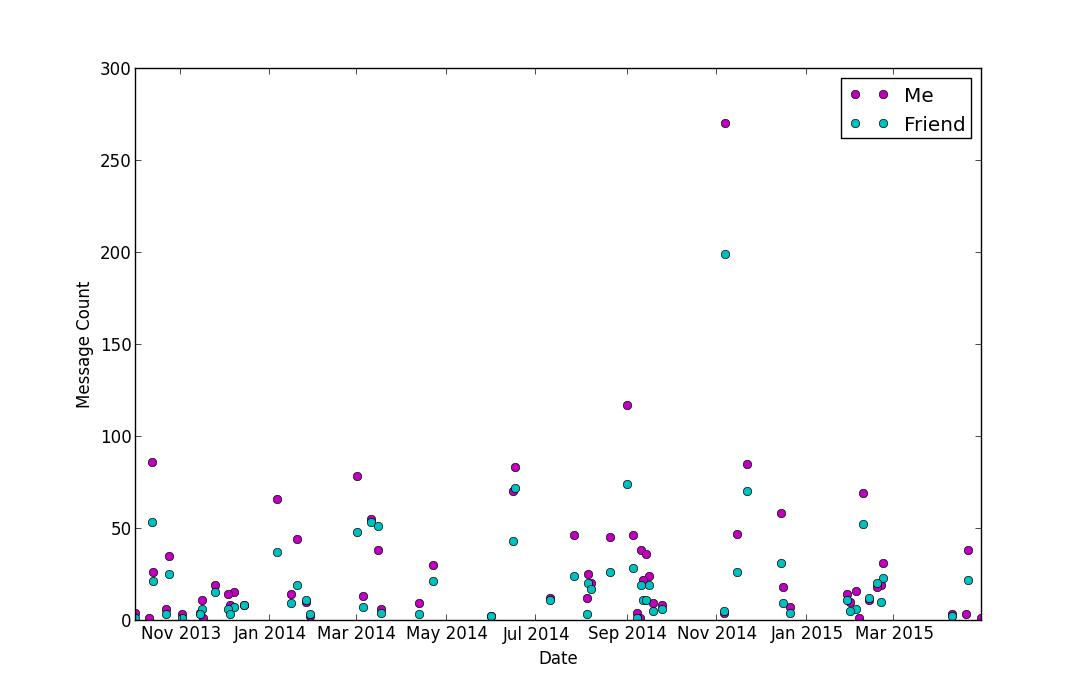


This is what i did, and that's about it. Find the accompanying code files on my GitHub profile: Vizualize WhatsApp Chat History.
Next step, vizualizing my Google History and Clustering it on the basis of title similarity.. Laters..
-Ankit Vadehra